Mit fast 86.000 Datenzeilen-Ergebnis aus der Vorerarbeitung des liturgischen Kalenders war mir schnell klar, dass diese Datenmenge nicht gut mit normalen Tabellenkalkulationsprogrammen zu verarbeiten ist – vor allem, wenn es um das komplexe Zusammenführen von Daten geht (frühere Tabellenkalkulationsprogramme eines Softwareherstellers aus Redmond konnten bis vor wenigen Jahren z.B. überhaupt nur etwa 65.000 Zeilen speichern/bearbeiten – ganz zu schweigen von der Berechnung).
Wie gerufen kam mir da die Programmiersprache R, mit der man super statistische Berechnungen vornehmen kann. Als grafische Benutzeroberfläche hab ich hierbei dann RStudio verwendet.
Die relativ steile Lernkurve zahlt sich auf jeden Fall aus. Ich habe für eine umfangreiche strategische Prognoseberechnung einmal Excel/LibreOffice Calc verwendet (mit SVerweis-Krücken etc.) – die beiden kamen ordentlich an ihre Leistungsgrenzen und kapitulierten entweder, oder brauchten selbst auf einem aktuellen Rechner etwa 30–45min Berechnungszeit. Mit R war die ganze Sache dagegen in etwa einer Minute getan. Berauschend!
Für einen guten Einstieg in R bietet z.B. der R‑Reader von Jörg Groß & Benjamin Peters. Die Cheatcheets/Schummelzettel sind aber auch sehr hilfreich!
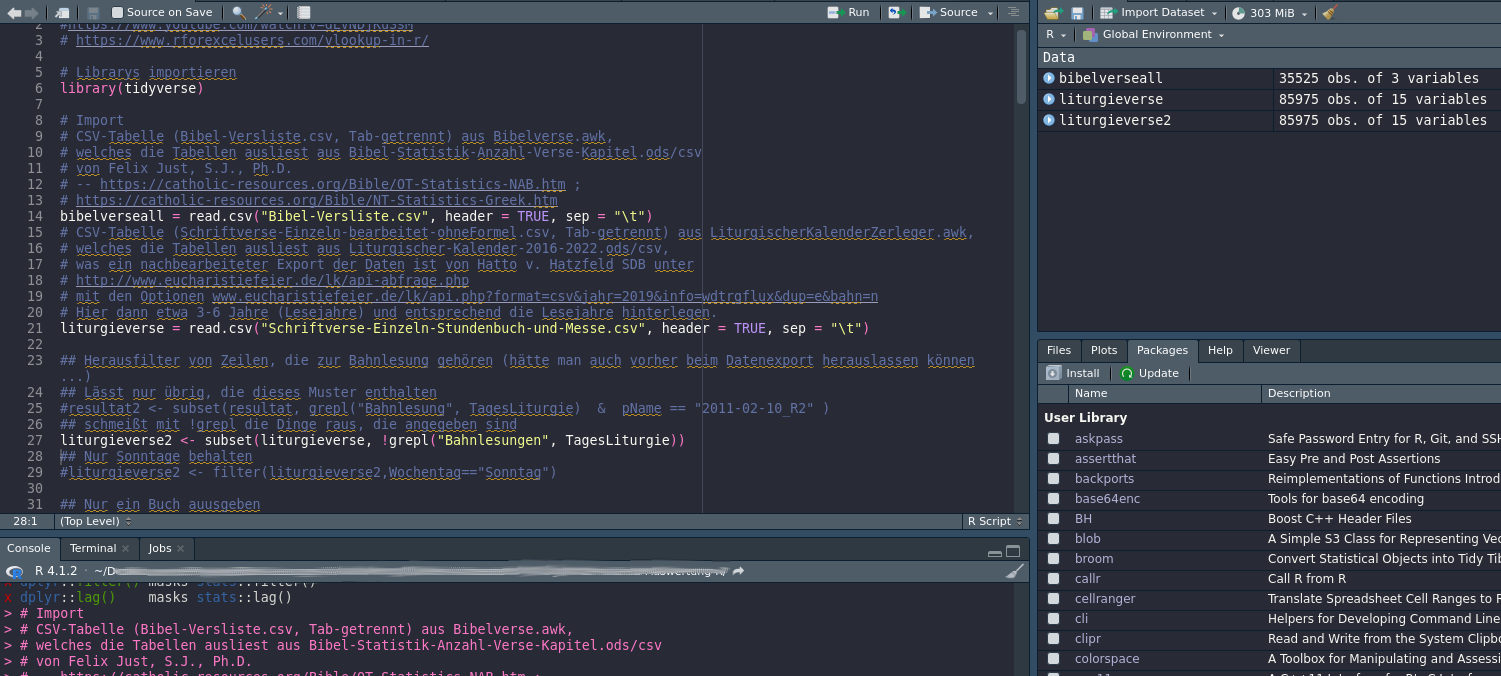
Folgend wieder einmal mein R‑Script – quick and dirty (Verbesserungen bitte gerne schreiben! Man kann viele Dinge auch kürzer machen, aber für die Lesbarkeit habe ich oft eine vielleicht umständlichere Variante verwendet). Die Import-Daten (also eine Tabelle mit allen einzelnen in der Leseordnung vorkommenden Bibelversen) findet sich weiter unten.
# Librarys importieren
library(tidyverse)
# Import
# CSV-Tabelle (Bibel-Versliste.csv, Tab-getrennt) aus Bibelverse.awk,
# welches die Tabellen ausliest aus Bibel-Statistik-Anzahl-Verse-Kapitel.ods/csv
# von Felix Just, S.J., Ph.D.
# -- https://catholic-resources.org/Bible/OT-Statistics-NAB.htm ;
# https://catholic-resources.org/Bible/NT-Statistics-Greek.htm
bibelverseall = read.csv("Bibel-Versliste.csv", header = TRUE, sep = "\t")
# CSV-Tabelle (Schriftverse-Einzeln-bearbeitet-ohneFormel.csv, Tab-getrennt) aus LiturgischerKalenderZerleger.awk,
# welches die Tabellen ausliest aus Liturgischer-Kalender-2016-2022.ods/csv,
# was ein nachbearbeiteter Export der Daten ist von Hatto v. Hatzfeld SDB unter
# http://www.eucharistiefeier.de/lk/api-abfrage.php
# mit den Optionen www.eucharistiefeier.de/lk/api.php?format=csv&jahr=2019&info=wdtrgflux&dup=e&bahn=n
# Hier dann etwa 3-6 Jahre (Lesejahre) und entsprechend die Lesejahre hinterlegen.
liturgieverse = read.csv("Schriftverse-Einzeln-Stundenbuch-und-Messe.csv", header = TRUE, sep = "\t")
## Herausfilter von Zeilen, die zur Bahnlesung gehören (hätte man auch vorher beim Datenexport herauslassen können ...)
## Lässt nur übrig, die dieses Muster enthalten
#resultat2 <- subset(resultat, grepl("Bahnlesung", TagesLiturgie) & pName == "2011-02-10_R2" )
## schmeißt mit !grepl die Dinge raus, die angegeben sind
liturgieverse2 <- subset(liturgieverse, !grepl("Bahnlesungen", TagesLiturgie))
## Nur Sonntage behalten
#liturgieverse2 <- filter(liturgieverse2,Wochentag=="Sonntag")
## Nur ein Buch auusgeben
liturgieverse3 <- filter(liturgieverse,Buch=="Ez")
liturgieverse3 <- subset(liturgieverse3, !grepl("Bahnlesungen", TagesLiturgie))
# Duplikate nach mehreren Spalten reduzieren, also wo mind. Buch, Kapitel und Vers gleich sind.
liturgieverse3 <- distinct(liturgieverse3,Buch,Kapitel,Vers,TagesLiturgie,.keep_all=TRUE)
write.csv2(liturgieverse3[order(liturgieverse3$Buch,liturgieverse3$Kapitel,liturgieverse3$Vers,liturgieverse3$TagesLiturgie), ], file = "ausgabe/liturgieverse-ezechiel.csv")
# Spalte ggf. umbenennen:
names(bibelverseall)[names(bibelverseall)=="Buch.kurz"] <- "Buch"
# Merge by multiple columns, Fügt die zwei Tabellen anhand mehrerer gleicher Spalten zusammen
resultat <- merge(bibelverseall, liturgieverse2, all.x = TRUE, by = c("Buch", "Kapitel", "Vers"))
# In CSV ausgeben
write.csv2(resultat, file = "ausgabe/alle-bibelverse-mehrmals-mit-leseordnung.csv")
# Duplikate nach mehreren Spalten reduzieren, also wo mind. Buch, Kapitel, Vers, TagesLiturgie gleich sind.
resultatAlle <- distinct(resultat,Buch,Kapitel,Vers,TagesLiturgie,.keep_all=TRUE)
# In CSV ausgeben
write.csv2(resultatAlle, file = "ausgabe/alle-bibelverse-mehrmals-mit-leseordnung-ohne-duplikate.csv")
# Häufigkeit der Verse berechnen
vershaeufigkeit <- resultatAlle %>% group_by(Buch, Kapitel, Vers) %>% summarize(count=n())
write.csv2(vershaeufigkeit, file = "ausgabe/vershaeufigkeit-im-gottesdienst.csv")
vershaeufigkeitsortiert <- vershaeufigkeit[order(vershaeufigkeit$count, decreasing = TRUE),]
write.csv2(vershaeufigkeitsortiert, file = "ausgabe/vershaeufigkeit-im-gottesdienst-sortiert.csv")
## Duplikate nach mehreren Spalten reduzieren, also wo mind. Buch, Kapitel und Vers gleich sind.
#resultat2 <- distinct(resultat,Buch,Kapitel,Vers,.keep_all=TRUE)
## In CSV ausgeben
#write.csv2(resultat2, file = "ausgabe/alle-bibelverse-nur-na.csv")
## Eine Art Pivottabelle -- Anzahl der Zeilen nach Buch und Kapitel
#resultat2 %>% count(Buch,Kapitel)
# Duplikate nach mehreren Spalten reduzieren, also wo mind. Buch, Kapitel und Vers gleich sind.
resultat3.1 <- distinct(resultat,Buch,Kapitel,Vers,TagesLiturgie,.keep_all=TRUE)
# Duplikate (wo die gleichen Bibelstellen mehrmals im Jahr vorkommen) zusammenführen in jeweils eine Zelle (DAUERT LANGE! Mehrere Minuten)
# filter(Buch=="Mk",Kapitel==3,Vers>=30) %>%
resultat3.2 <- resultat3.1 %>%
group_by(Buch,Kapitel,Vers) %>%
summarise(TagesLiturgie = paste(unique(TagesLiturgie), collapse = ', '),
Wochentag = paste(unique(Wochentag), collapse = ', '),
Bemerkungen = paste(unique(Bemerkungen), collapse = ', '),
Lesungstyp = paste(unique(Lesungstyp), collapse = ', '),
Farbe = paste(unique(Farbe), collapse = ', '),
Grad = paste(unique(Grad), collapse = ', '),
Rang = paste(unique(Rang), collapse = ', '),
Datei = paste(unique(Datei), collapse = ', '))
write.csv2(resultat3.2, file = "ausgabe/alle-bibelverse-mit-leseordnung-zusammengefasst.csv")
# Gibt die Versanzahl pro Buch aus
resultat3.2 %>% group_by(Buch) %>% summarise(VerseInsg=n())
# erstellt eine neue Tabelle aus resultat3 und fügt dieser eine weitere Spalte hinzu, in der geschaut wird,
# ob in der Spalte Rang nichts (NA) steht, und setzt hier 1/FALSE bzw. 0/TRUE (wird später für die Berechnung gebraucht, deshalb hier 1 für NA=FALSE)
#resultat4 <- cbind(resultat3.2,"VersNA"=ifelse(resultat3.2$Rang=="NA",0,1))
resultat4 <- cbind(resultat3.2,"VersNA"=ifelse(resultat3.2$Lesungstyp=="NA",0,1))
write.csv2(resultat4, file = "ausgabe/alle-bibelverse-zusammengefasst-mit-na.csv")
# erstellt eine neue Tabelle aus resultat 4
resultat5 <- resultat4
# Die Spalten, die gleich zusammengefügt werden sollen vom Text in eine Spalte
cols <- c( 'Buch' , 'Kapitel' , 'Vers' )
# Erstellt die neue Spalte `biblevers`, in die die drei Spalten zusammengefügt werden
resultat5$biblevers <- apply( resultat5[ , cols ] , 1 , paste , collapse = " " )
# Fügt die neue Spalte "Vers1" hinzu, die einfach nur jeweils den Wert 1 hat (für Berechnung)
resultat5$Vers1 <- 1
####
# Bibelbuchstatistik mit zusaetlichen Infos anreichern (NT/AT etc.)
# Dateien einlesen
#bibelbuchverstatistik = read.csv("resultat5.csv", header = TRUE)
bibelbuchverstatistik = resultat5
# Bei fehlendem Tabellenheader "FALSE" bei header nicht vergessen und dann diesen später hinzufügen (2. Zeile)
anzahlbibelverse = read.csv("Bibel-Statistik-Anzahl-Verse-Kapitel.csv", header = FALSE, sep = "\t")
# holt nur die Angaben jeweils zum Buchnamen in Lang- und Kurzform, sowie zum groben Teil der Bibel und AT/NT heraus.
anzahlbibelversekurz <- anzahlbibelverse[,c(2,3,156,157)]
# noch den Tabellenheader / Spaltenbeschriftung hinzufügen:
colnames(anzahlbibelversekurz) <- c("BuchName","Kurz","TeilderBibel","AT.NT")
# fügt noch eine ID ein, damit man die Buecher nachher in der richtigen Reihenfolge sortieren kann
anzahlbibelversekurz$id <- 1:nrow(anzahlbibelversekurz)
# zusammenfuehren mit mehreren Spalten (Buch und Buch-kurz) -- reichert die Komplettausgabe an mit Angaben zu AT/NT, Teil der Bibel etc.
ntatverse <- merge(bibelbuchverstatistik, anzahlbibelversekurz, by.x = "Buch", by.y = "Kurz")
# ausgeben
write.csv2(ntatverse, file = "ausgabe/verse-im-gottesdienst.csv")
# gruppiert die Einträge nach AT/NT-Spalte und errechnet die jeweilige Prozentangabe für AT/NT im Gottesdienst
# die Summe von Vers1 sind alle Verse pro Buch, die Summe von VersNA sind nur alle Verse, die tatsächlich vorkommen
ntatsum <- ntatverse %>% group_by(AT.NT) %>% summarise(Theorie=sum(Vers1),Gelesen=sum(VersNA),NichtGelesen=Theorie-Gelesen,ProzentGelesen=1/Theorie*Gelesen*100)
write.csv2(ntatsum, file = "ausgabe/bibel-at-nt-im-gottesdienst-prozent.csv")
# gruppiert die Einträge nach Teil-der-Bibel-Spalte und errechnet die jeweilige Prozentangabe für Teil-der-Bibel im Gottesdienst
# die Summe von Vers1 sind alle Verse pro Buch, die Summe von VersNA sind nur alle Verse, die tatsächlich vorkommen
ntatteilesum <- ntatverse %>% group_by(TeilderBibel) %>% summarise(Theorie=sum(Vers1),Gelesen=sum(VersNA),NichtGelesen=Theorie-Gelesen,ProzentGelesen=1/Theorie*Gelesen*100)
#ntatteilesum2 <- merge(anzahlbibelversekurz, ntatteilesum, by.x = "TeilderBibel", by.y = "TeilderBibel")
write.csv2(ntatteilesum[order(ntatteilesum$TeilderBibel), ], file = "ausgabe/bibel-teile-im-gottesdienst-prozent.csv")
# gruppiert die Einträge nach Bücher-Spalte und errechnet die jeweilige Prozentangabe für Bibelbücher im Gottesdienst
# die Summe von Vers1 sind alle Verse pro Buch, die Summe von VersNA sind nur alle Verse, die tatsächlich vorkommen
ntatbuechersum <- ntatverse %>% group_by(Buch) %>% summarise(Theorie=sum(Vers1),Gelesen=sum(VersNA),NichtGelesen=Theorie-Gelesen,ProzentGelesen=1/Theorie*Gelesen*100)
ntatbuechersum2 <- merge(anzahlbibelversekurz, ntatbuechersum, by.x = "Kurz", by.y = "Buch")
write.csv2(ntatbuechersum2[order(ntatbuechersum2$id), ], file = "ausgabe/bibel-buecher-im-gottesdienst-prozent.csv")
#nach mehreren Kriterien sortierte Liste exportieren
write.csv2(ntatbuechersum2[order(ntatbuechersum2$Prozent, decreasing = TRUE), ], file = "ausgabe/bibel-buecher-im-gottesdienst-prozent-sortiert.csv")Weitere Teile der Reihe zur statistischen Bibelvisualisierung:
Teil 0: Übersicht
Teil 1: Beschaffung der Daten
Teil 2: Datenaufbereitung mit einem Python-Programm (liturgischer Kalender / Heilige Messe)
Teil 3: Beschaffung der Daten zum Stundenbuch und Datenaufbereitung
Teil 4: Verarbeitung der Daten mit der Statistik-Programmiersprache R
Teil 5: Visualisierung der Daten mit RAW Graphs und Inkscape
Teil 6a: Endergebnisse
Teil 6b: Datentabellen
1 Kommentar Schreibe einen Kommentar